Couldn't load pickup availability
ABX-tech
即将面临系统设计面试者:
如果你即将面临系统设计面试,本书将帮助你迅速掌握分布式系统的核心知识,提升面试中的自信和应对能力。
技术提升追求者:
对于那些希望进一步提升自己技术水平的读者,本书将带领你深入了解分布式系统的理论和实践,助你技术更上一层楼。
分布式系统项目探索者:
如果你计划开展一个分布式系统项目,却不知道如何着手,本书将为你提供丰富的实战案例和理论知识,启发你找到合适的切入点。
分布式系统爱好者:
对于对分布式系统感兴趣的读者,本书将带你领略分布式系统领域的魅力,满足你的好奇心和求知欲。
论文阅读挑战者:
如果你曾尝试阅读分布式系统论文,却感觉难以理解,本书将以深入浅出的方式带领你逐篇解读经典论文,让你轻松掌握论文中的关键观点和技术细节
现如今大量Junior SDE的面试也会夹杂一些系统设计的面试问题。很多同学对于很多技术栈的认知都停留在只会用API上,对于实际开发中是如何使用的,以及底层的架构实现都是一无所知。一面试就挂掉。用DynamoDB来举例。这是一个很常用的技术栈,很多人都会用,但如果你问他为什么dynamo的设计可以支持高并发读写?为什么需要一致性哈希算法?高可用性和可伸缩性是如何实现的?Replication是如何实现的?怎么确保数据保证一致性?fault-tolerance又是如何通过gossip 协议实现的?可以说是一问三不知。
只要你的简历上写了DynamoDB相关的项目,面试官很大概率会问到你以上的相关的问题。绝大多数人都是答不上来的,但如果你能答上来,那么你就会占据巨大的优势。
但是话又说回来,如果让同学们亲自去读论文,大家又很难读进去,读懂就更难了。所以为了帮助大家更轻松的读懂论文,理解复杂系统的底层架构,我结合我个人大量的实际开发经验制作了这个带读详解合集。
这个合集整理了了多个分布式系统的论文、实践经验以及案例分析。这些系统都是主流互联网公司用来管理和处理海量数据的核心技术,不仅具有高可扩展性和高可用性,还能够处理各种结构化、半结构化和非结构化数据。其中的案例涉及了多个行业和领域,如音乐、电商、云计算、在线视频和智能推荐等。你可以通过这些案例了解到这些系统在实际应用中的表现和效果,以及它们是如何解决大规模数据处理和存储的难题的。通过学习这些系统,你将掌握分布式系统的核心思想、设计原理和实现细节,为你在分布式系统领域的学习和工作奠定坚实的基础。
合集当中除了有对每篇论文我自己的理解以外,所有晦涩难懂的名词都有单独的附录注解。比如高可用性,CAP theorem,replication等等,帮助你更高效的理解论文到底在讲什么。附录也会随着越来越多的名词出现,不断更新。
这个合集每周更新一篇论文,每个月提价一次。一次购买后永久可以阅读内容更新。持续更新,目标更新10+年。 (付款后直接有下载链接)购买了这份带读详解的同学,私信我进专属学习交流群。
当前更新目录如下:(还未更新的内容已经标为斜体并换色,是未来每周的更新计划。)
实战项目:
- Implement a real-time chat app
- Implement a distributed rate limiter
- Implement a distributed ID generation Service
- Implement a distributed web crawler
- Implement a notification service
- Implement a feed generation service
- Implement a distributed file store
- Implement a real-time telemetry(metric tracking) service
- Implement a real-time leaderboard
- Dynamo: Amazon’s Highly Available Key-value Store
- DynamoDB 是干什么的?
- DynamoDB的底层架构是什么样的?
- 论文里的主要核心思想哪有那些?
- DynamoDB的实现细节有哪些?
- DynamoDB的主要应用场景有哪些?
- DynamoDB常见实际场景系统设计面试题目:
- 题目1: 某公司使用DynamoDB作为其实时聊天应用的后端存储。为了满足高并发和低延迟的需求,你需要优化该数据库的配置。
- 题目2: 假设你正在开发一个基于DynamoDB的电商平台,需要处理大量的订单数据。由于订单状态可能会频繁发生变化,这可能导致多个节点上的数据发生冲突。请设计一个基于DynamoDB的订单处理流程,解决数据冲突的问题,并说明实现原理。
- 题目3: 假设你正在开发一个在线游戏平台,需要使用DynamoDB来存储玩家的数据。游戏平台有多个游戏,每个游戏都有不同的属性和排行榜。考虑到DynamoDB的查询能力和性能限制,如何设计一个可扩展且高效的数据模型,以支持以下需求
- 实战项目
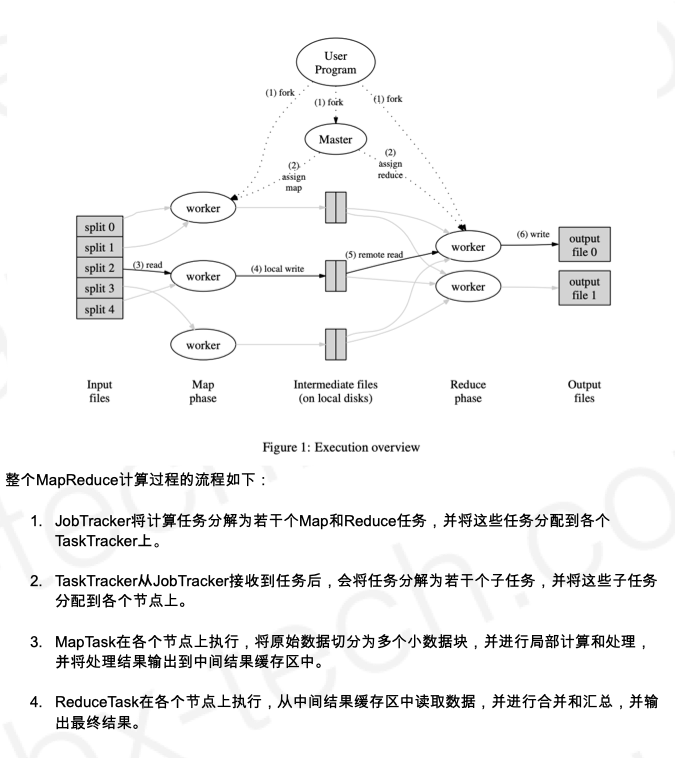
- MapReduce: Simplified Data Processing on Large Clusters
- MapReduce是干什么的?
- MapReduce的底层架构是什么样子的?
- MapReduce论文里的介绍了哪些核心思想?
- MapReduce的主要应用有哪些?
- MapReduce 常见实际场景系统设计面试题目:
- 题目1: 假设你正在使用MapReduce处理一个大型日志文件,其中包含了大量用户的访问记录。你的任务是分析每个用户在一段时间内的访问次数。请设计一个简单的MapReduce算法来实现这个功能,并描述其工作原理。
- 题目2: xxxxxxxxxx
- 题目3: xxxxxxxxxx
- 题目4: 假设你正在为一个电商公司开发一个商品推荐系统,需要使用MapReduce对大量用户行为数据进行处理和分析。你的任务是计算每个商品的用户喜欢程度,以便为用户推荐热门商品。请设计一个MapReduce算法来实现这个功能,并描述其工作原理。
- 题目5: xxxxxxxxxx
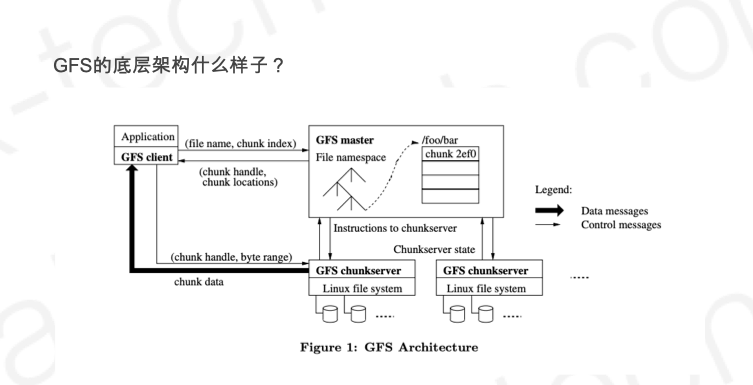
- The Google File System
- Google File System是干什么的?
- GFS的底层架构什么样子?
- GFS的实现细节是什么样的?
- GFS的论文讲了哪些核心思想?
- GFS的主要应用有哪些?
- GFS常见实际场景系统设计面试题目:
- 题目1: 在我们的公司中,我们使用Google File System (GFS)来存储和处理大量的数据。我们在对某个文件进行修改时,发现了一种情况:文件的某个部分被修改了,但是这个修改没有被复制到其他备份(replica)上。请解释这可能是什么原因导致的,以及GFS是如何处理这种情况的。
- 题目2: xxxxxxxxxx
- 题目3: xxxxxxxxxx
- 题目4: xxxxxxxxxx
- 题目5: xxxxxxxxxx
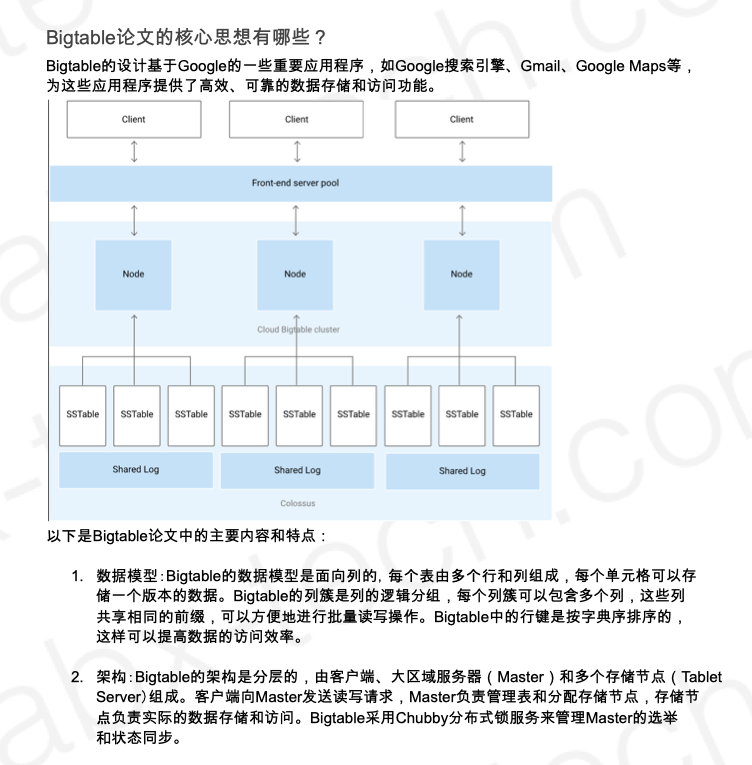
- Bigtable: A Distributed Storage System for Structured Data
- Bigtable是干什么的?
- Bigtable的底层架构是什么样的?
- Bigtable论文的核心思想有哪些?
- 论文里的SSTable有什么用?
- Bigtable的主要应用有哪些?
- Cassandra - A Decentralized Structured Storage System
- Cassandra是干什么的?
- Cassandra的底层架构是什么样的?
- Cassandra论文里有哪些核心思想?
- Cassandra的主要应用有哪些?
- Cassandra常见实际场景系统设计面试题目:
- 题目一:我们公司正在使用Cassandra来处理大量的读写请求,但是在高峰时段,我们发现读操作的性能有些下降。你能否从Cassandra的角度,给出一些可能的原因以及你的优化建议呢?
- 题目二:xxxxx
- 题目三:假设我们的产品需要实时统计用户的行为数据,xxxxx
- 题目四:xxxxx
- 题目五:xxxxx
- ZooKeeper: wait-free coordination for internet scale systems
- ZooKeeper是干什么的?
- Zab 算法是什么?
- ZooKeeper的底层架构是什么样子的?
- ZooKeeper论文的核心思想有哪些?
- ZooKeeper 有哪些实际应用?
- The Hadoop Distributed File System
- Hadoop Distributed File System (HDFS) 是干什么的?
- HDFS底层框架是什么样的?
- HDFS论文的核心思想是什么?
- HDFS有哪些实现细节?
- HDFS是如何有效地实现大规模数据的并行写入的?
- HDFS在各大行业中的应用场景有哪些?
- Kafka: a Distributed Messaging System for Log Processing
- Kafka的底层架构是怎么样的?
- Kafka论文的核心思想有哪些?
- Kafka有哪些重要的实现细节?
- Kafka是如何利用Zookeeper的?
- Kafka在各大行业中的应用场景有哪些?
- CAP Twelve Years Later: How the "Rules" Have Changed
- CAP定理是什么?论文大概说了一件什么事?
- 这篇论文的核心思想有哪些?
- 为什么CAP定理很重要?
- CAP定理在实际开发中的案例有哪些?
- 在实际开发中是如何权衡CAP定理的?
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
- AWS Aurora是什么, 为什么需要用Aurora?
- Aurora的底层架构什么样子?
- 这篇论文的核心思想有哪些?
- Aurora 和 Vitess 的区别是什么?我应该用哪个?
- AWS Aurora在各大领域中的实际开发案例
- Spanner: Google's Globally-Distributed Database
- Spanner是什么?
- Google Spanner 有哪些特性?
- Google Spanner的底层架构是什么样子的?
- Paxos在spanner中的应用
- TrueTime API实现原理是什么?
- Spanner是否打破了CAP定理?
- Spanner的实际开发案例
- Time, Clocks and the Ordering of Events in a Distributed System
- 为什么这篇论文被誉为分布式系统的基石?
- 这篇论文中你需要知道的概念有哪些?
- 全局时钟(Global Clock)与局部时钟(Local Clock)
- 事件的偏序(Partial Order)关系
- Lamport 时间戳(Lamport Timestamps)与逻辑时钟(Logical Clocks)
- 一致性条件(Consistency Conditions)
- 有哪些理论和框架是受到该论文启发所研究出来的?
- Sparrow: Distributed, Low Latency Scheduling
- Sparrow是什么?为什么需要Sparrow?
- Sparrow的底层架构是什么样子的?
- Sparrow的实现细节
- Sparrow有哪些应用场景?
- 有哪些业界著名框架收到了Sparrow的启发?
- Apache Spark: A unified engine for big data processing
- Apache Spark是什么?
- 这篇论文的核心思想有哪些?
- Apache Spark的底层架构是什么样子的?
- Apache Spark有哪些实现细节?
- Apache Spark在各个行业领域中的实际应用有哪些?
- AI领域是如何应用Apache Spark的?
- Apache Spark: A unified engine for big data processing
- Apache Spark是什么?
- 这篇论文的核心思想有哪些?
- Apache Spark的底层架构是什么样子的?
- Apache Spark有哪些实现细节?
- Apache Spark在各个行业领域中的实际应用有哪些?
- AI领域是如何应用Apache Spark的?
附录涵盖内容如下:
- 什么是分布式系统?
- 什么是CAP Theorem?
- 什么是NoSQL 数据库?
- 什么是Service-Oriented Architecture?
- 分布式系统当中的去中心化是什么?
- 什么是高可扩展(伸缩)性(High Scalability)?
- 什么是高可靠性(High Reliability)?
- 什么是高可用性(High Availability)?
- 什么是容错性(Fault-tolerance)?
- 什么是冗余(Redundancy)?
- 什么是鲁棒性(Robustness)?
- 什么是负载均衡(Load Balancing)?
- 什么是分片(Sharding)?
- 什么是Resharding?
- 什么是分区(Partitioning)?
- 什么是事务处理(Transaction Processing)?
- 什么是隔离性(Isolation)?常见的隔离级别有哪些?
- Bloom Filter是什么?
- 结构化数据,半结构化数据和非结构化数据分别是什么?
- 负载均衡的策略有哪些?
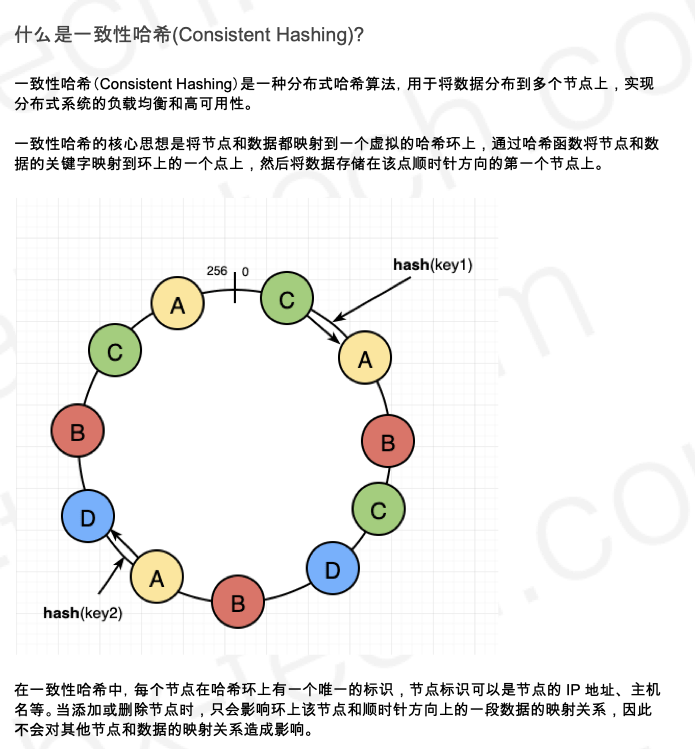
- 什么是一致性哈希(Consistent Hashing)?
- 数据一致性(Consistency)是什么?都有哪些种类?
- 副本复制(Replication)是什么?
- 副本复制延迟(Replication Lag)是什么?
- 什么是流言协议(Gossip Protocol)?
- 多数派共识(Quorum Consensus)怎么理解?
- 心跳机制(Heartbeat Mechanism)是什么?
- 前向错误纠正(FEC)是什么?
- Paxos算法是什么?
- 选举领导者(Leader Election)怎么回事?
- 分布式锁(Distributed Lock)是怎么回事?
- 流处理平台是什么?
- 什么是时钟漂移"(Clock Drift)?
- 什么是资源竞争(Resource contention)?
- 什么是瞬时负载波动(Transient Load Fluctuations)?
系统设计面试真题:
- 大数据存储和分析系统设计
- 大型电商系统设计
- 分布式限流器设计
- 分布式事务处理系统
- 分布式日志收集系统
- 分布式ID生成系统
- 分布式缓存问题
- 分布式配置管理系统
ABX
小红书ID: 5239818020